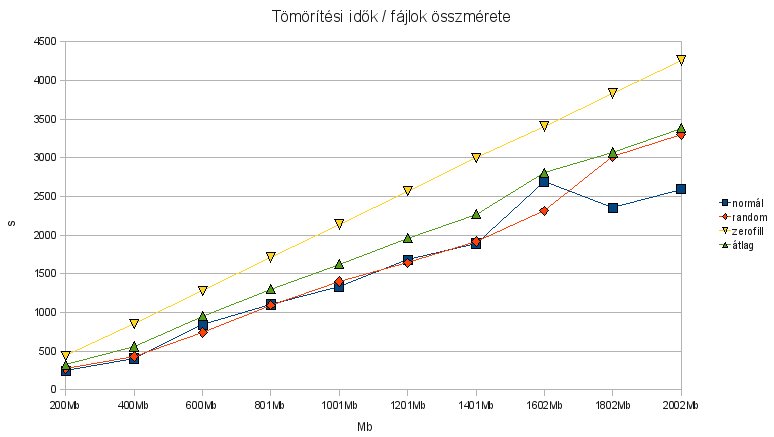
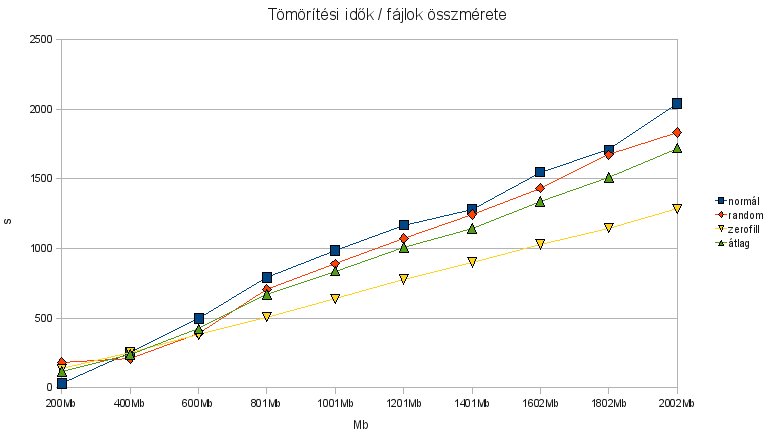
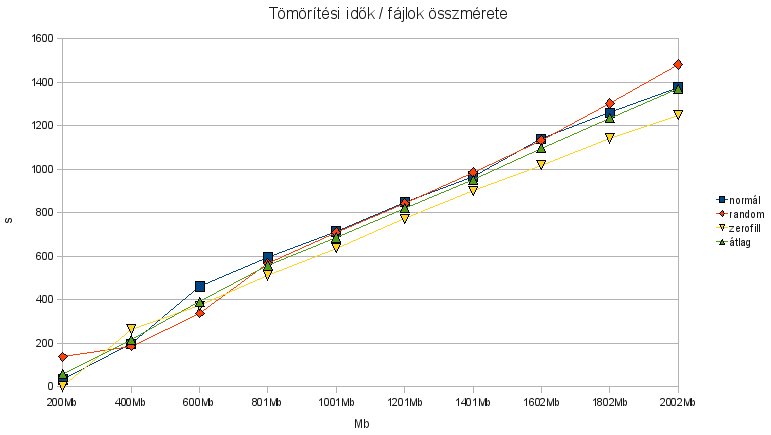
Bevezetőként: Eredeti elképzelésem szerint ez a különféle tömörítési algoritmusokat összehasonlító kis cikkecske egyetlen rész lett volna, de önálló életet élve kezdett túlburjánzani. Miközben elkezdtem kiagyalni hogy hogyan végezzem el a tesztet, rájöttem hogy csak az eredmények közzététele egy nagy rakás post lehetne - ettől eltekintek, most leírom hogy miért kezdtem bele a dologba, és hogy hogyan teszteltem. Ez alapján akárki, sokkal jobb gépen is újratesztelhet, vagy más algoritmusokat is ki tud próbálni. Sőt, ha valaki alá tudja támasztani/cáfolni tudja az itt leírtakat, hallasson magáról, köszi.
Gondolkodtam sokat, hogy van ez a sokféle tömörítő algoritmus, vajon miért használom folyton a .tar.gz-t? Annyira megszoktam, hogy automatikusan rááll a kezem. A bzip2 jobb tömörítési arányt ad, mint a gzip, de sokkal számításigényesebb is, és én valahogy sosem voltam ellátva nagyon hardverrel - vagyis lehet hogy csak nem szántam rá a pénzt. Tudom, tudom, most már igazán megengedhetnék magamnak egy Pentium 3-ast, elég olcsók... :-DDDD
Félretéve a hülyéskedést, a bzip2 nagyon jó, heurisztikát is alkalmazó algoritmus de csak fájlt tud alapból tömöríteni, könyvtárat nem; ugyanígy a gzip is csak fájlokkal tud foglalkozni - de mint tudjuk (vagyis amint sulykolják belénk, a kifejezés tetszés szerint megválasztható), a *NIX éppen azért jó, mert olyan programokból épül fel, amelyek egyetlen feladatra alkalmasak, de arra nagyon jók - és ezeket a rugalmas Linux/*BSD rendszerekben könnyű összekapcsolni. Tehát ott van a tar, ami egy fájlt képez, és ugyanabban a lépésben az elkészülő tar-ra ráeresztjük a gzipet/bzip2-t, és elkészült a tömörített egyetlen fájl a sok könyvtárból. No igen, egy óriási hátránnyal.
Tudja valaki, hogy a tar (azon kívül, hogy kátrányt jelent), minek a rövidítése? Tape ARchive. És miről ismeretesek a régi szalagos egységek? Backupra használták őket, és szekvenciális a hozzáférés. Azaz ha egy olyan adat kell, ami a tar fájl, vagyis a szalag végén van, akkor bizony végig kell tekerni az egészet.
Vissza kellett párl apró fájlt állítanom nemrégiben, és a home-om egyetlen összecsomagolt, 4Gb-os .tar.gz-ben volt elmentve. A hajam kihullott, mire egyáltalán a fájl listát ki tudtam íratni, mert pontosan nem emlékeztem a fájlnevekre. A kitömörítéshez természetesen ismét fel kellett nyálazni az egész fájlt. Ekkor már a saját fejemet csapkodtam egy lédús citromszelettel...
Ami felmerült bennem ama vészterhes éjszakai órán: MI A HALÁLÉ' NEM HASZNÁLOK ÉN ZIP-et?! Hát, próbáljuk meg.
Ezután kezdtek az elburjánzások: először is haversrác benyögte hogy miért nem tesztelem akkor a 7zip-et is? (Kellett nekem emlegetni, hogy mi lesz a következő blogpostom... ;) minenesetre a 7zip-et majd máskor.) Ahogyan gondolom mindenki aki mérnöki képzésen esett át, én is megtanultam méréstechnikából, hogy egy mérés nem mérés és páratlan számú mérést kell végezni, szóval minimum három futam kell. Ebből nyilván nagy rakás eredmény is született; az pedig tényleg csak a legkevesebb hogy egy héten keresztül futott éjjel-nappal a teszt... :-)
Licensz kérdések
Szeretek egy témát több irányból körbenyalni, így első körben utánanéztem a licensznek. Lehet hogy a licensz miatt kellene az OSS közösségnek össznépileg leköpködnie a ZIP készítőit?
Meglepő, de a licensz nem vészes. Ez egy módosított 3-pontos BSD licensz; amely engedélyezi a használatot bármilyen formában, illetve a forráskód terjesztését és módosítását mindaddig, amíg a licenszet mellékelik, valamint a program is ki tudja írni a licenszfeltételeket (magyarul a licensz hiánytalan kiírásának lehetőségét nem lehet kitörölni a forrásból). Még van egy könnyítés is, mert a 3-as pontot kivették (de beletettek egy pontot az önkicsomagoló futtatható ZIP-ek miatt); ezen kívül megnevezték a bejegyzett neveket, amelyeket csak az általuk kiadott forrású program viselhet - ez is érthető; ha én beleírok valami általam tákolt algoritmust a forrásukba, ne nevezhessem a továbbiakban info-zipnek. Innentől nekem ez egyáltalán nem különbözik a FreeBSD operációs rendszer kétfeltételes módosított licenszétől... Mivel a ZIP forrása letölthető, ezért mindig lesz olyan program majd ami ki tudja csomagolni a .zip fájlokat.
Kezelhetőség
Pár apró példa a parancssori kezelésre; illetve ahogyan én használtam (a bzip2-t és a gzip csak egy betűben tér el úgyhogy csak az egyiket írtam oda):
| Művelet | ZIP | BZIP2/GZIP |
| Egy fájl tömörítés* | zip -Tm <zipfájl> <fájlnév> | bzip <fájlnév> |
| Több fájl/könyvtár** | zip -r <zipfájl> <fájlnév1> <fájlnév2> ... | bzip2 <fájlnév1> <fájlnév2> |
| Több fájl/könyvtár tar segítségével | tar cf - <fájlnév1> <fájlnév2> | zip test.zip - | tar cjvf <fájlnév1> <fájlnév2> ... |
| Archívum titkosítása*** | zip -e | - |
| Sérült archívum helyreállítása | zip -F <zipfájl>
zip -FF <zipfájl> | zcat
bzip2recover |
| Szelektív tömörítés (megadhatók fájl kiterjesztések amiket nem próbál meg tömöríteni, pl. amik egyéb módon már tömörítve vannak, így gyorsabb lesz)**** | zip -n .7z:.tiff:.flac <zipfájl> <fájlok> | - |
| Archívum tesztelése | zip -T <zipfájl> | bunzip2 -t |
| Archívum tesztelése tar-on keresztül | unzip -p <zipfájl> | tar tf - | tar tjf <bzfájl> |
| Archívum kitömörítése***** | unzip <zipfájl> | tar xjf <bzfájl> |
* Mivel a bzip2 és a gzip is bemozgatja a fájlt, ezért a zipet is így paraméterezem.
** A ZIP megkülönbözteti a *.* és a * wildcard-okat, előbbi csak azokat tömöríti amelyeknek VAN kiterjesztésük. A gzip, bzip2 nem tud könyvtárakat tömöríteni
*** A ZIP a pkzip módszert használja, ami nem teljesen biztonságos.
****Ez a ZIPnél megadható környezeti változóban is, ami nagyon hasznos
*****A parancs után megadható(k) a kitomorítendő fájl(ok); teljes elérési úttal és akkor szépen létrejönnek a könyvtárak és bele a megfelelő fájlok. Példa: unzip test.zip alma/almakompot.txt
Nekem nincs igazán nagy különbség a kezelésben - lássuk a sebességtesztet!
Teszt módszertan: Sebesség, tömörítési arány
Hah, pártos szellemek! Itt az igazi kérdés...!
Aki az eredményekre kíváncsiak és nem igazán köti le őket a dolog technikai vonatkozása, azok kérem, várjanak a következő postig; akit pedig érdekelnek hogy hogyan készítettem a teszteket, vagy esetleg meg akarják ismételni őket, szóval azok folytassák az olvasást:
1. A nagy kisfájl-teszt
Első ötlet, hogy készítek sok kicsi (és majdan kevés nagy) fájlokból álló könyvtárakat, és ezeket tömörítem össze, illetve csomagolom ki teljesen ugyanazon a hardveren. Mivel egy mérés nem mérés stb. ezért három mérést kellett elvégeznem, de úgy gondoltam akkor már ne legyen ez a három teszt egyforma, hanem különféle jellegű fájlok legyenek ezek és majd tudok átlagot vonni a különféle körülmények között végzett eredményekről:
1.1 "Normál", vagyis "hétköznapi" fájlok. Mivel tervem szerint a méretezhetőség miatt minden könyvtárban pontosan 10,000 darab, ugyanakkora méretű fájl kellett legyen, ezért annyit csináltam, hogy végighaladtam a dokumentum könyvtáramon, amiben vannak PDF doksik, DOC-ok, képek, HTML, néhány rövidecske videó stb. szóval tökéletes mixe a közönséges fájloknak; ezeket a fájlokat összemásoltam egyetlen fájllá, majd ezt szétdaraboltam 20,000 bájtos fájlokra. Így egy könyvtárban éppen 10,000*20,000 bájt, azaz közel 200Mb van.
find ~/Documents -type f -exec cat {} >> oriasfile.raw \;
for i in `seq 10000`; do let a=i*20000; dd if=oriasfile.raw of=$i".txt" bs=1 skip=$a count=20000 status=noxfer; doneMegjegyzés: tudom, hogy van egy split parancs is, ami kb. ezerszer gyorsabb, viszont nem tudtam rájönni hogy azzal hogyan tudok 100-nál több fájlt legyártani - csak annyit volt hajlandó. Ha valaki elárulja, update-elem itt ezt a ronda részt a dd-vel.
1.2 Random fájlok. Készítettem az előzőekkel megelőző méretű és számú fájlokat, csak ezeket egy Perl szkript hozta létre, random ASCII karakterekkel feltöltve. Mint kiderült, a fájlok entrópiája kb. ugyanaz maradt, ezért a tömörítési arányok megegyeztek 200Mb és 2Gb esetén is... hát, ennyit a régebbi PC-k entrópiájáról úgy általában.
#!/usr/bin/perl
for($l=1;$l<=10000;$l++){
if(open (OUTFILE,">./$l.txt")){
for($i=0;$i<10000;$i++){
my ($genNum)=join('', ('.', '/', 0..9, 'A'..'Z', 'a'..'z')[rand 64, rand 64]);
print OUTFILE $genNum;
}
close(OUTFILE);
if($l%100==0) { print "$l.txt\n";}
}else { die "$l. file nem megnyithato"; }
}1.3 Zerofill, azaz nullával feltöltött fájlok, megegyező méretben és számban, mint eddig. Természetesen itt számítottam a legerősebb tömörítési arányra, ami nyilván be is jött hiszen kb. annyit kellett csak eltárolni, hogy "állíts vissza 20,000 darab 0-t". A véletlengeneráló perl szkriptből ezt már tényleg egyszerű volt előállítani:
#!/usr/bin/perl
for($l=1;$l<=10000;$l++){
if(open (OUTFILE,">./$l.txt")){
for($i=0;$i<10000;$i++){
print OUTFILE "0\n"
}
close(OUTFILE);
if($l%100==0) { print "$l.txt\n";}
}else { die "$l. file nem megnyithato"; }
}Összesen 10 könyvtárnyit gyártottam ezekből a fájlokból - természetesen a normál, random és zerofill tesztet úgy végeztem, hogy legeneráltam a szükséges fájlokat, lefutott a teszt majd letöröltem a könyvtárakat; hogy az új fájlok a merevlemezen is kb. ugyanoda kerüljenek, tehát az elérési sebesség ne nagyon változzon. (Jó, nem töröltem a fájlokat hiszen még jók lesznek azok pl. 7zipet tesztelni, hanem csak elmentettem őket másik merevlemezre.)
Most már minden rendelkezésre állt, hogy tömöríthessek különféle programokkal, 200Mb - 2Gb terjedelemig. Ezt is tettem. :-) Ennek menete kb. ez volt:
- 0. Fájlok legenerálása az előbb említett módon
- 1. Egy ciklus a tömörítendő könyvtárakkal, mindig egy újabbat beletéve
- 2. Ellenőrzés: Ha már futott ez a teszt, nem futtatjuk újra
- 3. Tömörítés, közben mérjük az időt
- 4. A betömörített fájl méretét eltesszük
- 5. Archívum teszt futtatása tar nélkül, mérjük az időt
- 6. Archívum teszt futtatása tar-ral, mérjük az időt
- 7. Egy fájlt, konkrétan az utolsó könyvtár utolsó fájlját kitömörítjük (szekvenciális elérésnél a legrosszabb eset)
Mindez konkrétan:
#!/bin/sh
for i in `seq 10`; do
if [ -f "gz_"$i"_time6.log" ]; then
echo "GZIP "$(seq 1 $i)" mar futott, kihagyva"
else
echo "GZIP "$(seq 1 $i)" start"
time -o "gz_"$i"_time.log" tar -czf test.tar.gz $(seq 1 $i)
ls -la test.tar.gz >> "gz_"$i"_time.log"
time -o "gz_"$i"_time2.log" gunzip -tv test.tar.gz >> "gz_"$i"_time3.log"
time -o "gz_"$i"_time4.log" tar -tzf test.tar.gz >> "gz_"$i"_time5.log"
time -o "gz_"$i"_time6.log" tar -xzf test.tar.gz $i/9999.txt
rm test.tar.gz
cat "gz_"$i"_time2.log" "gz_"$i"_time4.log" "gz_"$i"_time6.log" >> "gz_"$i"_time.log"
echo "GZIP "$(seq 1 $i)" kesz"
sleep 30
fi
done
for i in `seq 10`; do
if [ -f "bz_"$i"_time6.log" ]; then
echo "BZIP "$(seq 1 $i)" mar futott, kihagyva"
else
echo "BZIP "$(seq 1 $i)" start"
time -o "bz_"$i"_time.log" tar -cjf test.tar.bz2 $(seq 1 $i)
ls -la test.tar.bz2 >> "bz_"$i"_time.log"
time -o "bz_"$i"_time2.log" bunzip2 -tv test.tar.bz2 >> "bz_"$i"_time3.log"
time -o "bz_"$i"_time4.log" tar -tjf test.tar.bz2 >> "bz_"$i"_time5.log"
time -o "bz_"$i"_time6.log" tar -xjf test.tar.bz2 $i/9999.txt
rm test.tar.bz2
cat "bz_"$i"_time2.log" "bz_"$i"_time4.log" "bz_"$i"_time6.log" >> "bz_"$i"_time.log"
echo "BZIP "$(seq 1 $i)" kesz"
sleep 30
fi
done
for i in `seq 10`; do
if [ -f "zt_"$i"_time6.log" ]; then
echo "ZIP w tar "$(seq 1 $i)" mar futott, kihagyva"
else
echo "ZIP w tar "$(seq 1 $i)" start"
time -o "zt_"$i"_time.log" tar cf - $(seq 1 $i) | zip test.zip -
ls -la test.zip >> "zt_"$i"_time.log"
time -o "zt_"$i"_time2.log" unzip -T test.zip >> "zt_"$i"_time3.log"
time -o "zt_"$i"_time4.log" unzip -p test.zip | tar tf - >> "zt_"$i"_time5.log"
time -o "zt_"$i"_time6.log" unzip -p test.zip | tar xf - $i/9999.txt
rm test.zip
cat "zt_"$i"_time2.log" "zt_"$i"_time4.log" "zt_"$i"_time6.log" >> "zt_"$i"_time.log"
echo "ZIP w tar "$(seq 1 $i)" kesz"
sleep 30
fi
done
for i in `seq 10`; do
if [ -f "z_"$i"_time6.log" ]; then
echo "ZIP "$(seq 1 $i)" mar futott, kihagyva"
else
echo "ZIP "$(seq 1 $i)" start"
time -o "z_"$i"_time.log" zip -rq test.zip $(seq 1 $i)
ls -la test.zip >> "z_"$i"_time.log"
time -o "z_"$i"_time2.log" unzip -T test.zip "bz_"$i"_time3.log"
time -o "z_"$i"_time6.log" echo "A" | unzip test.zip $i/9999.txt
rm test.zip
cat "z_"$i"_time2.log" "z_"$i"_time6.log" >> "z_"$i"_time.log"
echo "ZIP "$(seq 1 $i)" kesz"
sleep 30
fi
doneA részeredmény fájlokat nem töröltem le, de összemálsoltam, így a gz_1_time.log fájlban van csak az első könyvtár gzip tömörítés tesztjének összes idő- és méreteredménye, a gz_2_time.log-ban az első és második könyvtár gzip-pel tömörítésének eredményei, a gz_10_time.log-ban pedig az összes könyvtár gzipes tömörítésének eredménye. Ugyanez "bz" előtaggal a bzip2 tesztet, "zt" a zip és tar, a sima "z" előtag pedig a ZIP teszt eredményeit tartalmazza.
A kódban látszik, hogy az idő mérésére a Linux "time" parancsát használtam, aminek kimenete valami ilyemi:
real 40m45.432s
user 6m36.769s
sys 18m11.364sFájlba kicsit másképp ír:
51.71user 42.11system 21:24.38elapsed 7%CPU (0avgtext+0avgdata 0maxresident)k
4093432inputs+33848outputs (0major+4911minor)pagefaults 0swapsAz eredményben benne van az eltelt idő századmásodperces pontossággal, a processzorhasználat és egyéb érdekes eredmények is, amik most minket nem érdekelnek. Jobban érdekelt, hogy hogyan fogok ebből én egy olvasható eredményt gyártani... :-) Végülis egy kis gyors Perl szkripttel egy CSV-t állítottam elő a fájlokból (ez azért is jó volt, mert az idő-adatokból másodperceket tudtam gyártani közben, amivel egyszerűbb hasonlítgatni). Íme a szkript, amin tudom hogy lehetne optimalizálni hiszen a nagyon hasonló if-es sorok összevonhatók lennének egy feltételbe, de nem érte meg fáradozni ezzel:
#!/usr/bin/perl
sub timetosec{
my $mytime;
$_ = shift;
if (/^([0123456789]*:[0123456789]*:[0123456789\.]*)$/){
$mytime = $1;
my ($myhour, $mymin, $mysec) = split(/:/, $mytime);
$mytime = $myhour*3600 + $mymin*60 + $mysec;
}
elsif(/^([0123456789]*:[0123456789\.]*)$/){
$mytime = $1;
my ($mymin, $mysec) = split(/:/, $mytime);
$mytime = $mymin*60 + $mysec;
}
$mytime =~ s/\./,/g;
return $mytime;
}
our $outfile;
my $prefix = $ARGV[0];
if ($prefix eq ''){
die ("Hasznalat: eval.pl <prefix>, ahol a prefix lehet z,gz,zt vagy bz.");
}
$outfile = "";
for($l=1;$l<=10;$l++){
if(open (INFILE,"<./".$prefix."_".$l."_time.log")){
my $linecount = 0;
while (<INFILE>) {
chomp;
if($_ ne '') {$linecount++;}
if($linecount == 1 && /^.*system (.*)elapsed ([0123456789]{1,3}).*$/){
$outfile .= timetosec($1).";".$2.'%;';
}
elsif($linecount == 3){
my ($rights,$hl,$owner,$group,$size,$date,$time,$name) = split(/\ /,$_);
$outfile.="$size;";
}
elsif($prefix ne "z" && $linecount == 4 && /^.*system (.*)elapsed.*$/){
$outfile .= timetosec($1).";";
}
elsif($prefix ne "z" && $linecount == 6 && /^.*system (.*)elapsed.*$/){
$outfile .= timetosec($1).";";
}
elsif($prefix ne "z" && $linecount == 8 && /^.*system (.*)elapsed.*$/){
$outfile .= timetosec($1).";";
}
elsif($prefix eq "z" && $linecount == 5 && /^.*system (.*)elapsed.*$/){
$outfile .= timetosec($1).";";
}
elsif($prefix eq "z" && $linecount == 7 && /^.*system (.*)elapsed.*$/){
$outfile .= timetosec($1).";";
}
}
close(INFILE);
$outfile.="\n";
}else { die "./".$prefix."_".$l."_time.log file nem megnyithato"; }
}
if(open (OUTFILE,">./".$prefix."__alldata.csv")){
print OUTFILE $outfile;
close(OUTFILE);
}else { die "./".$prefix."__alldata.csv file nem megnyithato. Irasi jog?"; }
Ez az ügyes szkript ezt a CSV-t állítja elő (odaírtam az oszlopok magyarázatát, de azt a perl szkript nem állítja oda elő:
tömörítés ideje, s;MaxCPU, %;méret, b;teszt ideje,s;tar teszt ideje,s;egy fájl kitömörítése,s;
0,19;6%;106;0,05;0,01;
263,17;9%;873969;2,18;2,86;2,59;
371,6;9%;1310952;3,08;4,28;3,83;
511,9;9%;1747093;4,13;5,73;5,17;
636,59;9%;2182006;5,19;7,21;6,39;
771,93;9%;2617890;6,08;8,53;7,69;
900,84;9%;3055217;7,11;9,88;8,98;
1019,14;9%;3494495;8,1;11,43;10,23;
1141,91;9%;3934047;8,97;12,83;11,5;
1248,41;9%;4377833;9,98;14,23;12,73;Ezt már az Openoffice-ba simán be tudtam hívni. Elnézést, hogy az elválasztójel pontosvessző a megszokott vessző helyett, de az OOO akkor ismerte fel tört számnak a másodperceket, ha nem pont, hanem vessző volt a tizedes határoló. Nyilván nem használhattam ugyanezt a vesszőt mezőhatárolónak, hiszen ... értitek.
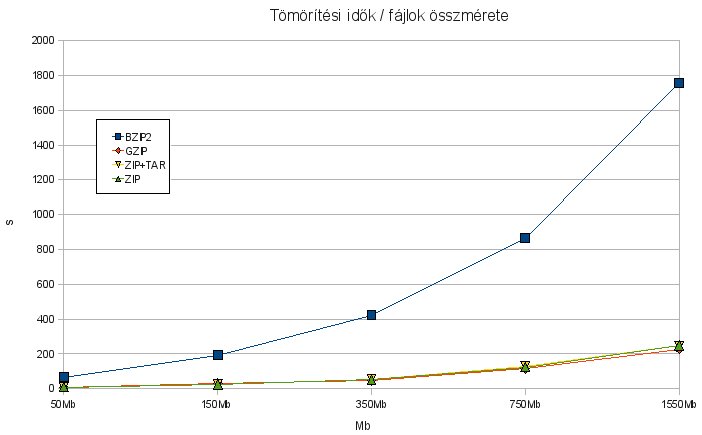
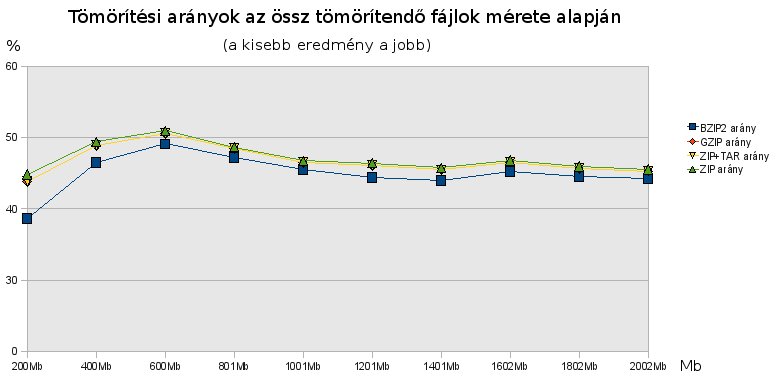
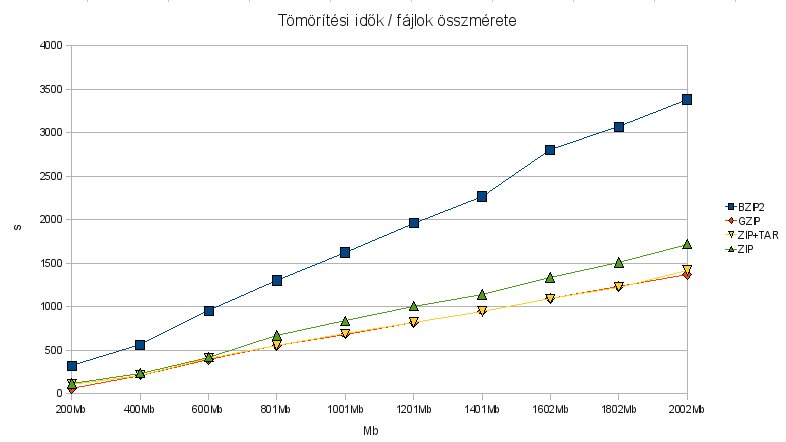
Innentől már csak játék volt az Openoffice-szal, hogy menő diagramokat állítsak elő. Előzetes a következő posthoz:
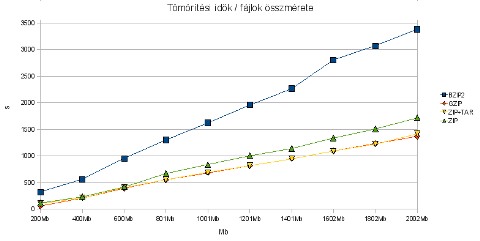
Holnap délben jelentkezem!